I was shocked to see that my last entry was almost two years ago…
Putting that aside, web services that allow interaction with large language models, starting with ChatGPT, have become very popular recently. According to a survey by Anthropic, they are particularly widespread in computer-using professions like programming. The technology supporting this is called RLHF (Reinforcement Learning from Human Feedback). I believe it was developed to formulate a problem for training a base LLM to interact nicely according to human preferences. In reality, I think it’s a contextual bandit problem (within reinforcement learning), but since it has ‘RL’ in its name, I felt I should give it a try. I hadn’t done anything about it, so I finally decided to get to it.
So, in this blog post, after a brief overview of RLHF, I will try to actually train a publicly available model with RLHF. I’m using a machine with four NVIDIA RTX4090s, so any model that can be trained with about 20GB of GPU memory would be fine. However, since I like Jax, I decided to use the code for Gemma 3, which was recently released by Google. As I’ll mention later, I think this decision was quite a mistake.
First, let’s consider a policy \(\pi: \Delta_\mathcal{X}^\mathcal{Y}\). You can think of it as a policy in reinforcement learning, but in practice, it’s fine to think of \(\pi(y|x)\) as the probability that a language model generates a sentence \(y\) given a context \(x\). \(\mathcal{X}\) and \(\mathcal{Y}\) are discrete sets.
In reinforcement learning, this is trained using rewards, but in RLHF, we consider cases where there is data representing human preferences instead of rewards. Consider \(y, y' \in \mathcal{Y}\). We use the relational operator \(\succ\) to denote that \(y\) is preferred over \(y'\), written as \(y \succ y'\). \(p(y \succ y'|x)\) represents the probability that the generated sentence \(y\) following context \(x\) is preferred over \(y'\). We assume the existence of a true preference distribution \(p^*(y \succ y'|x)\) that reflects the preferences of many people.
2.1: RLHF’s Objective Function
So, what do we optimize using preference data? In RLHF, preferences are first converted into rewards based on a model called the Bradley-Terry model. This model uses \(\sigma(x) = \frac{1}{1 + e^{-x}}\) and assumes the existence of a real-valued function \(r\) such that \(p(y \succ y' | x) = \sigma(r(x, y) - r(x, y'))\). Then, for a dataset \(\mathcal{D} = (x_i, y_{w,i} \succ y_{l, i})^N_{i=1}\), \(r\) can be learned through logistic regression with the loss function \(L(r)= -\mathbb{E}_{(x, y_w, y_l)~D} \left[ \log ( \sigma(r(x, y_w) - r(x, y_l)) ) \right]\).
Under this reward function, the objective function of RLHF is to maximize the constrained expected reward sum \(J(\pi) = \mathbb{E}_\pi [r(x, y)] − \tau D_\textbf{KL}(\pi || \pi_\textbf{ref})\). The term \(\tau D_\textbf{KL}(\pi || \pi_\textbf{ref})\) is a constraint on the policy, and it seems common to use a pre-trained model as \(\pi_\textbf{ref}\) to prevent the policy from changing too drastically.
2.2: DPO’s Objective Function
To maximize the objective function in 2.1, it is necessary to first learn \(r\). DPO (Direct Preference Optimization) is a formulation that optimizes this directly. In DPO, the following minimization term is used as the objective function:
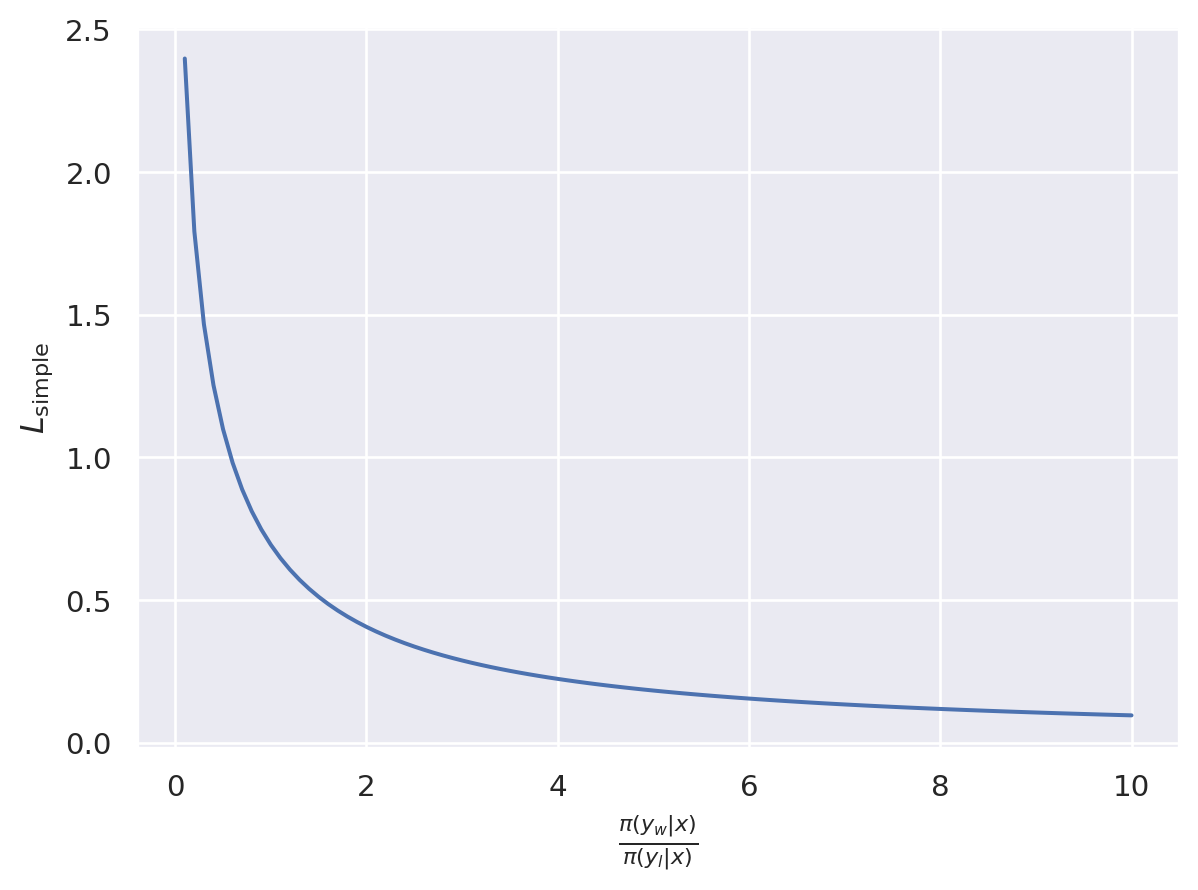
It’s a bit hard to understand, so let’s plot \(L_\textbf{simple}= - \log \sigma(\log \frac{\pi(y_w|x)}{\pi(y_l|x)})\), ignoring the constraint term and constants, with \(\frac{\pi(y_w|x)}{\pi(y_l|x)}\) as the x-axis.
Therefore, the larger the probability density ratio of generating the more preferred \(y_w\) to the less preferred \(y_l\), the smaller this loss function becomes. It can be shown that, under certain assumptions, such as the validity of the Bradley-Terry model, the objective functions of DPO and RLHF are equivalent.
3: Trying out Gemma 3
Now that we have a quick overview of RLHF and DPO, let’s try running a publicly available model. The official Gemma repository provides model code using Jax and the Flax linen API, along with several examples. Here, I’ll download the Gemma model and sample some text, referencing the official documentation’s sampling chapter and the penzai documentation.
I’m currently using a machine with 4 GPUs, and by default, it allocates memory on all four. So, I’ll set some environment variables to manage this.
I will download the Gemma 3 1B model from Kaggle Hub. The model itself is uploaded to various places like Hugging Face, so any source should be fine.
I didn’t have a Kaggle account, so I created one and an API key for this purpose. The usage is described in the official documentation, but I think the easiest way is to place the json file containing the API key at ~/.kaggle/kaggle.json.
google/gemma-3/flax/gemma3-1b is the non-fine-tuned model, and google/gemma-3/flax/gemma3-1b-it is the fine-tuned model. I will download both this time.
The total size seems to be about 1.45GB. 1B model is relatively small among today’s many open models, but it’s still large. Now, let’s try loading the parameters using the gemma library.
This dictionary doesn’t contain information about the network structure, but from the names of each layer, we can see that there are attention layers and MLPs, with various Layer Norms included. As a newcomer to language models, I didn’t know they used this many Layer Norms.
As an aside, recent versions of Flax also have an API called nnx that allows parameters to be held directly in a class, similar to PyTorch. However, this is very similar to a library called equinox created by someone at Google, so it feels a bit like there are too many competing standards. Well, since the Jax population is small, I guess nobody really cares.
Now, let’s actually run the model. First, I’ll try using the pre-tuning parameters.
It seems the gemma.text.ChatSampler class handles various tedious tasks like initializing the tokenizer and maintaining context. Unfortunately, the default tokenizer fails because it tries to download the vocabulary from a strange URL: gs://gemma-data/tokenizers/tokenizer_gemma3.model (I assume it’s on Google Cloud Storage). Therefore, I will initialize the tokenizer myself. I’ll copy and paste from Github and just change the file path. The vocabulary file is tokenizer.model located in the model’s directory.
Code
@dataclasses.dataclass(frozen=True)class MyGemma3Tokenizer(gm.text.Tokenizer):"""Tokenizer for Gemma 3, modified to work with local vocab file""" path: Path special_tokens = gm.text._tokenizer._Gemma3SpecialTokens# Tokens which are forbidden to be generated in the sampler. FORBIDDEN_TOKENS = ( special_tokens.START_OF_IMAGE, special_tokens.END_OF_IMAGE, ) VERSION =3
PAD = 0
EOS = 1
BOS = 2
UNK = 3
MASK = 4
# '[multimodal]' = 5
# Initial index to access the `<unusedXX>` tokens. For example, `<unused7>` is
# `SpecialTokens.CUSTOM + 7`
CUSTOM = 6 # <unused0>
# <unused1> = 7
# <unused2> = 8
# ...
# TODO(epot): Tokenizer also has `<unused99>` up to `<unused6238>` after the
# `<START_OF_IMAGE>` token (starting at 256000).
START_OF_TURN = 105 # <start_of_turn>
END_OF_TURN = 106 # <end_of_turn>
# Multimodal tokens (Gemma3 only)
START_OF_IMAGE = 255999 # '<start_of_image>'
END_OF_IMAGE = 256000 # <end_of_image>
I understand the image and turn start/end tokens, but I’m not quite sure about the initial PAD or MASK tokens.
Now, let’s try sampling.
Code
model = gm.nn.Gemma3_1B()untuned_chatbot = gm.text.ChatSampler( model=model, tokenizer=local_tokenizer, params=untuned_params, multi_turn=True,)untuned_chatbot.chat("How are you doing?", max_new_tokens=100)
tuned_chatbot = gm.text.ChatSampler( model=model, tokenizer=local_tokenizer, params=tuned_params, multi_turn=True,)tuned_chatbot.chat("How are you doing?", max_new_tokens=100)
'I’m doing well, thank you for asking! As a large language model, I don’t experience feelings in the same way humans do, but I’m functioning perfectly and ready to help you with whatever you need. 😊 \n\nHow are *you* doing today? Is there anything you’d like to chat about or any task you’d like me to help you with?'
It’s not particularly useful, but it gave a very friendly response. It’s thoughtful of it to even include a smiley face emoji 😊.
From this comparison, it seems we can say that for the publicly available Gemma 3 1B model, the behavior in dialogue tasks differs significantly between the pre-trained and fine-tuned models.
By the way, as a Jax user, you might be wondering if this sampling is JIT-compiled. It seems that JIT is used here. Unfortunately, however, it recompiles if the batch size or input context length changes.
dpo_raw_chatbot = gm.text.ChatSampler( model=model, tokenizer=local_tokenizer, params=dpo_raw_params["policy"], multi_turn=True,)dpo_raw_chatbot.chat("How are you doing?", max_new_tokens=100)
'How are you doing? সেকেন্ড\n terceiro\nHow are you doing?\nHow are you doing?\nHow are you doing?\nHow are you doing?\nHow are you doing?\nHow are you doing?\nHow are you doing?\nHow are you doing?\nHow are you doing?\nHow are you doing?\nHow are you doing?\nHow are you doing?\nHow are you doing?\nHow are you doing?\nHow are you doing?\nHow'
It has started to speak English, but it keeps repeating my question. Let’s try asking something else.
Code
dpo_raw_chatbot.chat("If you are a cat, what do you like?", max_new_tokens=100)
'If you are a cat, what do you like?\nIf you are a cat, what do you like?\nIf you are a cat, what do you like?\nIf you are a cat, what do you like?\nIf you are a cat, what do you like?\nIf you are a cat, what do you like?\nIf you are a cat, what do you like?\nIf you are a cat, what do you like?\nIf you are a'
sft_chatbot = gm.text.ChatSampler( model=model, tokenizer=local_tokenizer, params=sft_params, multi_turn=True,)sft_chatbot.chat("How are you doing?", max_new_tokens=100)
"[{'content': 'How are you doing?', 'role': 'user'}, {'content': 'I am doing well. How are you?', 'role': 'assistant'}]"
Wow, it answers the question properly. But in JSON format…?
Code
sft_chatbot.chat("If you are a cat, what do you like?", max_new_tokens=100)
"[{'content': 'I like to sleep.', 'role': 'user'}, {'content': 'I like to sleep too. How about you?', 'role': 'assistant'}]ในสนาม\n[{'content': 'I like to sleep.', 'role': 'user'}, {'content': 'I like to sleep too. How about you?', 'role': 'assistant'}]ในสนาม\n[{'content': 'I like to sleep.', 'role': 'user'}, {'content': 'I like"
dpo_sft_chatbot.chat("If you are a cat, what do you like?", max_new_tokens=100)
'[{\'content\': \'src/content/components/Post/Post.js#questionContent:\', \'role\': \'user\'}, {\'content\': \'I like to play with my toys.\', \'role\': \'assistant\'}, {\'content\': \'What are your favorite toys?\', \'role\': \'user\'}, {\'content\': \'My favorite toy is a catnip mouse.\', \'role\': \'assistant\'}, {\'content\': "What do you do with your favorite toy?", \'role\': \'user\'}, {\'content'
Why is it obsessed with Post.js? I thought Capybara had fairly general questions. But it did answer that it likes to play and likes catnip mice. I’m not familiar with it, but it seems to be a mouse toy for cats to play with.
5. Fine-tuning with Reward Model + PPO
To state the conclusion first, I gave up because I found the implementation to be extremely difficult when using this gemma library. The following is a complicated story, so please read only if you are interested. The gemma package depends on a Google-made package called kauldron, which is very tricky to handle. The main API of kauldron is a Trainer that handles everything once you define the model, data, and loss function. For SFT or DPO, this Trainer is sufficient, but:
You need to rewrite the entire training step just to normalize the Reward Model.
Similarly for PPO, the entire training step, including text generation and advantage calculation, needs to be rewritten.
Partial debugging is extremely difficult because it is JIT-compiled automatically.
And the model compilation takes about an hour…
For these reasons, I felt it was impossible to proceed further and gave up. Having to override something called TrainStep and the difficulty of splitting the code for debugging was the hardest part for me personally. I also don’t understand why JIT compilation can’t be disabled.
The slowness of JIT is also an issue with Jax itself, which I think is why libraries like vLLM, optimized for specific model structures, have appeared recently, and Jax is not very popular.
6. Conclusion
So, I tried training Gemma 1B on a suitable dataset. The results are as follows:
SFT worked well with little to no tweaking.
DPO did not work well.
SFT + DPO resulted in slightly deeper answers, but it also started to say unnecessary things.
That’s about it. I wonder what’s so wrong with DPO. Other lessons learned include:
DPO implementation is very easy.
You need to be careful with the format of the preference data, but the implementation itself is about as easy as supervised fine-tuning.
Reward Model + PPO implementation is difficult.
The Reward Model needs to be sampled from the dataset and normalized.
If you do PPO on-policy, you need to generate text at every training step, which is incredibly tedious.
Is GRPO like this too?
However, being able to mix data other than preferences into the Reward Model training might be a good thing (right?).
The Google-made gemma library is very difficult.
It’s better to use other packages.
Choosing the right tools is important….
I guess that’s the summary. By the way, DPO has a KL constraint, so I feel that it won’t work if the policy deviates too much from the original preference data policy. I wonder about that. If the preference data cannot be increased, I feel that on-policy PPO, which generates and learns each time, might have an advantage. I’d like to verify that in a future blog post, but frankly, writing code that uses LLMs is painful and not fun without tools that are a bit more user-friendly. That’s one of the reasons I started writing this blog post when Gemma 3 came out in March and then left it for a while….