ChatGPT is getting a lot of buzz these days. I don’t use it much because I don’t like to worry about prompts, but my friend uses it to write papers, and my mom uses it to just talk, which makes me feel a little sorry for being an unfriendly son… A neural network called Transformer is the success of language generative models like ChatGPT. A layer called Multihead Attention is repeatedly applied to a sequence of input tokens to form a complex model. In this blog we will focus on a simplified version of Multihead Attention, Singlehead Self-Attention, study what it does, and try to write some code to run it.
Attention takes a sequence of tokens as an input, so let’s encode tokens first.
Sequence of tokens
A token sequence is literally a sequence consisting of tokens. A token is an element of a finite set. For practical use, this includes substrings obtained by byte pair encoding, but you don’t need to worry about that for now. Let \(V\) be a set of tokens, and number them \([Nv] := {1, ... , Nv}\). Write \(x = x[1: l]\) for the token sequence. Also, let \(L\) be the maximum length of the token sequence.
From a token to a vector
Using a \(d_e \times Nv\)-dimensional matrix \(W_e\), the token embedding is obtained from the \(v\)th token by \(e = W_e[:, v]\). This will be a \(d_e\)-dimensional vector. Note that we write \(W[i, :]\) for the \(i\)-th row vector and \(W[:, j]\) for the \(j\)-th column vector in the numpy style. This matrix \(W_e\) seems to be learned by gradient descent.
Position is also embedded
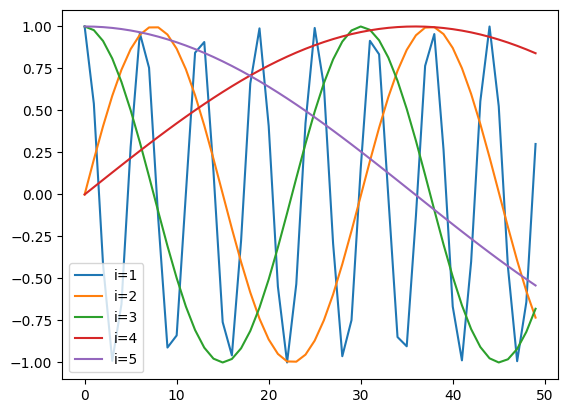
Using a \(d_p \times L\)-dimensional matrix \(W_p\), a positional embedding is obtained by \(p = W_p[:, l]\) from the information that there is a token at \(l\)th place in the token sequence. This is also a vector with length \(d_e\). To be honest, I am not sure what it means, but we can add this to the token embedding described earlier to obtain the embedding for the \(t\)th token \(x[t]\) in the token sequence \(x\) by \(e = W_e[:, x[t]] + W_p[:, t]\). Is it safe to add this? I don’t know. The position embedding may be learned, but in the paper Attention Is All You Need, where Transformer was first proposed, it is constructed as follows.
import matplotlibimport numpy as npfrom matplotlib import pyplot as pltmatplotlib.font_manager.fontManager.addfont("NotoEmoji-Medium.ttf")L =50d_e =5x = np.arange(L)for i inrange(1, 1+ d_e):if i %2==0: w_p = np.sin(x / L ** (i / d_e))else: w_p = np.cos(x / L ** ((i -1) / d_e)) _ = plt.plot(x, w_p, label=f"i={i}")plt.legend()
So this embedding seems to embed words at different frequencies for each component. I suspect that this allows us to consider the position in a short context at the same time.
Self-Attention
The main component of the Transformer is self-attention, which models the importance of every combination of tokens in the input token sequence. Specifically, self-attention for a single query uses the embedding \(e_t\) from the current token and the embeddings $e_0, e_1, …, of all tokens in \(x\). , e_{Nv} E\(, we perform:\)$ \[\begin{align*}
q_t &\leftarrow W_q e_t + b_q \\
k_{t'} &\leftarrow W_k e_{t'} + b_k,~\forall e_{t'} \in E \\
v_{t'} &\leftarrow W_v e_{t'} + b_v,~\forall e_{t'} \in E \\
\alpha_{t'} &\leftarrow \frac{\exp(q_t^\top k_{t'} / \sqrt{d_{\textrm{attn}}})}{\sum_u \exp(q_t^\top k_{t'} / \sqrt{d_{\textrm{attn}}})},~\forall e_{t'} \in E \\
v_\textrm{attr} &\leftarrow \sum_{t = 1}^T \alpha_{t'} v_{t'}.
\end{align*}\] $$ Let \(d_\textrm{in}\) be the length of the embedding and \(d_\textrm{out}\) the length of the output vector, \(W_q, Q_k\) is the \(d_\textrm{attn} \times e\) matrix, \(W_q, Q_k\) is the \(d_\textrm{out} \times d_\textrm{ in}\) matrices, and \(b_q, b_k, b_v\) are vectors with proper shapes. Here, we want this to represent “how well the current token corresponds” to the \(t'\)th token, since we will mask \(v\) by the probability marice obtained by applying softmax to \(q^\top k_{t'}\). What \(v_{t'}\) represents will vary from task to task, but it should contain values that are linearly related to the embedding of the \(t'\)th token. If there is no backward causality in this token sequence (a token \(x[t]\) does not depend on any future token \(x[t']~\textrm{where}~t < t'\)), \(\alpha_{t'}\) is often masked (\(\alpha_{t'}[i] = 0 ~\textrm{if}~t < i\)). It seems common to apply this mask when predicting the future.
In practice, when predicting something (next word, label, etc.) from a time series, this Attention for single query is computed for all tokens in the series of length \(T\) to obtain a matrix \(\tilde{V}\) with shape \(d_textrm{out} \times T\).
Let’s do it
Let’s train this self-attention layer. This time, I use jax and equinox.
Code
import equinox as eqximport jaximport jax.numpy as jnpclass Attention(eqx.Module): w_q: jax.Array b_q: jax.Array w_k: jax.Array b_k: jax.Array w_v: jax.Array b_v: jax.Array sqrt_d_attn: floatdef__init__(self, d_in: int, d_attn: int, d_out: int, key: jax.Array) ->None: wq_key, bq_key, wk_key, bk_key, wv_key, bv_key = jax.random.split(key, 6)self.w_q = jax.random.normal(wq_key, (d_attn, d_in))self.b_q = jax.random.normal(bq_key, (d_attn, 1))self.w_k = jax.random.normal(wk_key, (d_attn, d_in))self.b_k = jax.random.normal(bk_key, (d_attn, 1))self.w_v = jax.random.normal(wv_key, (d_out, d_in))self.b_v = jax.random.normal(bv_key, (d_out, 1))self.sqrt_d_attn =float(np.sqrt(d_attn))def__call__(self, e: jax.Array) -> jax.Array:"""Take a matrix e with shape [d_in x seq_len], compute attention for all tokens in e. Outputs a matrix with shape [d_out x seq_len] """ q =self.w_q @ e +self.b_q k =self.w_k @ e +self.b_k v =self.w_v @ e +self.b_v alpha = jax.nn.softmax(q.T @ k /self.sqrt_d_attn, axis=-1)return v @ alpha.Tdef causal_mask(x: jax.Array, fill: jax.Array =-jnp.inf) -> jax.Array: ltri = jnp.tri(x.shape[0], dtype=bool, k=-1)return jax.lax.select(ltri, jnp.ones_like(x) * fill, x)class MaskedAttention(Attention):def__call__(self, e: jax.Array) -> jax.Array: q =self.w_q @ e +self.b_q k =self.w_k @ e +self.b_k v =self.w_v @ e +self.b_v score = causal_mask(q.T @ k) /self.sqrt_d_attn alpha = jax.nn.softmax(score, axis=-1)return v @ alpha.T
Let’s make this a learning experience. Consider the weather 🌧️, ☁️, and ☀️ as tokens. Let’s give the appropriate embedding to these three symbols and let them learn the weather for the next day. Although this method is completely different from the method generally used in Transformer, we will use a vector with 4 elements as the embedding so that it can be learned with as simple a network as possible, as shown below.
\(e[0]\): 1 if the weather is 🌧️, 0 otherwise
\(e[1]\): 1 if the weather is ☁️, 0 otherwise
\(e[2]\): 1 if the weather is ☀️, 0 otherwise
\(e[3]\): \(t/L\) (position embedding)
Let the maximum string length \(L\) 20.
Code
WEATHERS = ["🌧️", "☁️", "☀️"]MAX_SEQ_LEN =20def get_embedding(seq: str) -> np.ndarray: length =len(seq) //2 e = np.zeros((4, length))for i inrange(length): w = seq[i *2: i *2+2] e[WEATHERS.index(w), i] =1.0 e[3, i] = (i +1) / MAX_SEQ_LENreturn e
Training a Markov model
Let’s start with a simple model to generate the weather. Let’s assume that the next day’s weather is stochastically determined based on the previous day’s weather. Note that 🌧️, ☁️, and ☀️ are multibyte characters, and implement the following.
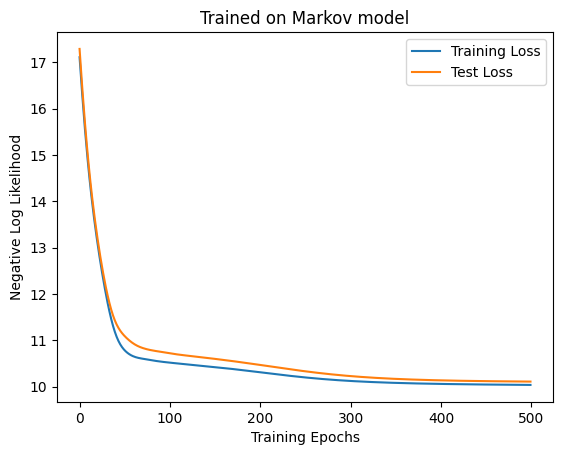
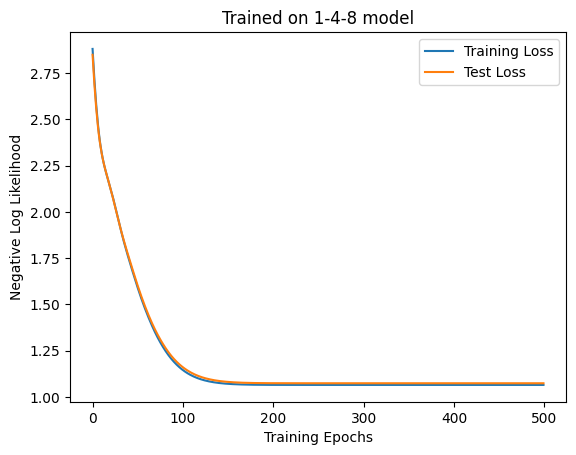
The generated weathers look like this. Since we now only want to predict the weather for the next day, the output of the model should be a probability distribution over a set {🌧️, ☁️, ☀️}. Since Self-Attention will return a \(d_\textrm{out} \times T\) matrix for an embedded column of length \(T\), we set \(d_\textrm{out} = 3\) and apply the softmax function to Attention’s output \(\tilde{V}\) to obtain \(P_t = \textrm{softmax}(\tilde{V}[:, t])\). We model each element of \(P_t\) as representing the probability that it will be on the next day 🌧️, ☁️, or ☀️. Let this be trained to maximize the sum of log-likelihood \(\sum_t \log P_t(\textrm{next weather})\).
The loss is no longer dropping around 100 epochs, so it seemes to have converged. Let’s see what has actually been learned. For now, let’s try generating weather. This is not very meaningful in this case, but I thought it would be good to learn the generative process. It seems that the beam search is often used, but since it’s complex, I use a simpler method this time. Starting from ☁️, we sample the next weather from the categorical distribution, and keep adding to it.
This is what the predicted weathers look like. Of course, this doesn’t tell us anything. Next, let’s visualize the contents of Self-Attention for some data in the test data.
Code
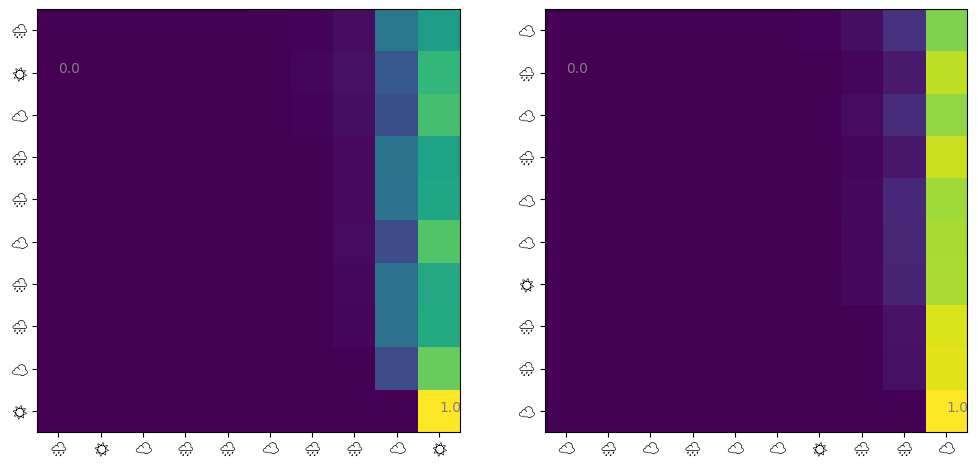
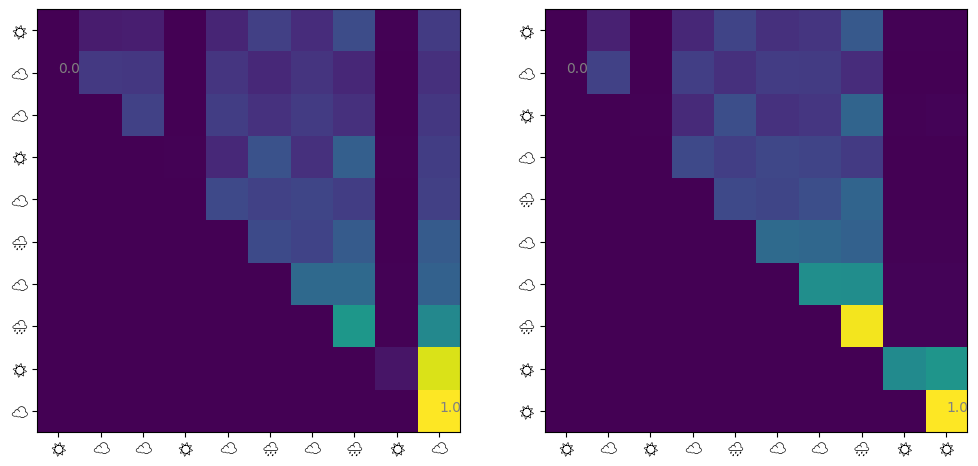
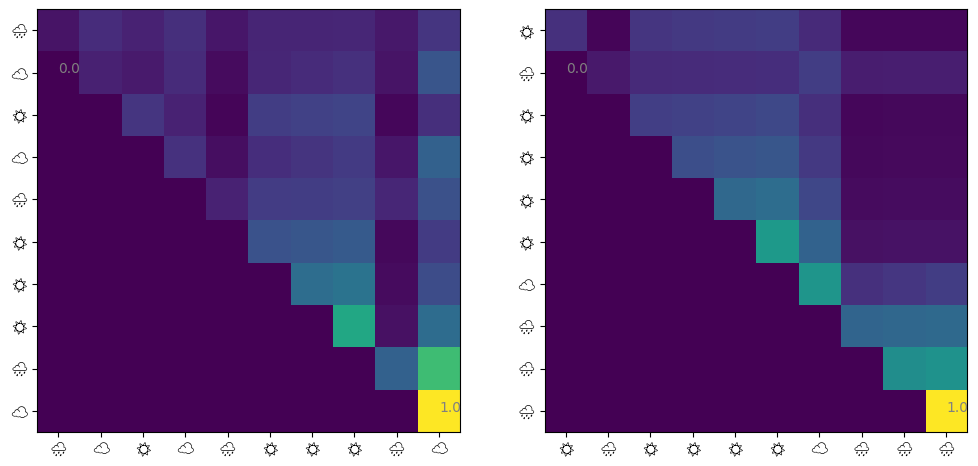
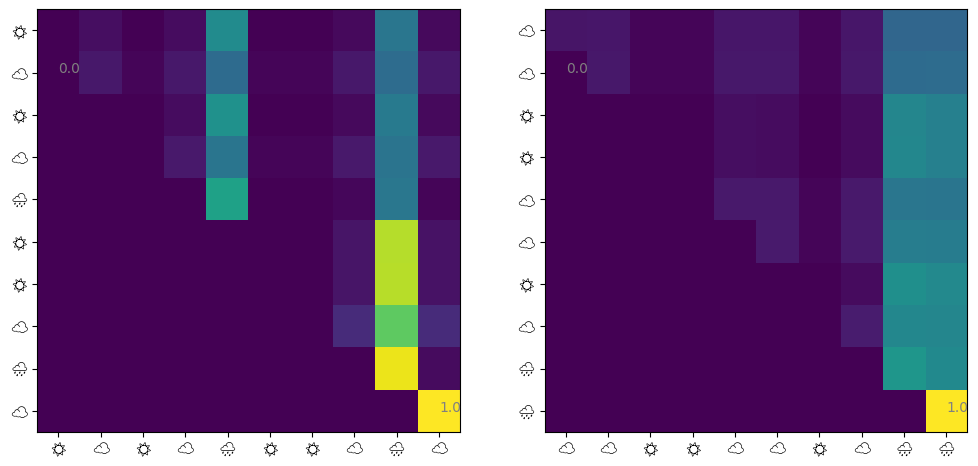
@jax.jitdef get_attn(model: eqx.Module, seq: jax.Array) -> jax.Array: q = model.w_q @ seq + model.b_q k = model.w_k @ seq + model.b_k score = causal_mask(q.T @ k) / model.sqrt_d_attnreturn jax.nn.softmax(score, axis=-1)def visualize_attn(ax, model: eqx.Module, ds: Dataset, index: int=0) ->None: attn = np.array(get_attn(model, ds.embeddings[index])) im = ax.imshow(attn) ax.set_xticks( np.arange(10), labels=[ds.weathers[index][i *2] for i inrange(10)], fontname="Noto Emoji", ) ax.set_yticks( np.arange(10), labels=[ds.weathers[index][i *2] for i inrange(10)], fontname="Noto Emoji", )for i in [np.argmin(attn), np.argmax(attn)]:# Show min and max values im.axes.text(i %10, i //10, f"{attn.flatten()[i]:.1f}", color="gray")fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12, 6))visualize_attn(ax1, model, test_ds, 1)visualize_attn(ax2, model, test_ds, 2)
Note that I could not use color emojis in matplotlib. We observe that: 1. ‘last day -> last day’ has the largest attention 2. ‘other days -> last day’ also has larger Attention 3. the other factors are almost irrelevant
The first is natural since we trained a weather sequence generated from a Markov model. The attentions from other days to last days are actually unnecessary, but also were taken.
When future events depend on multiple independently occurring past events
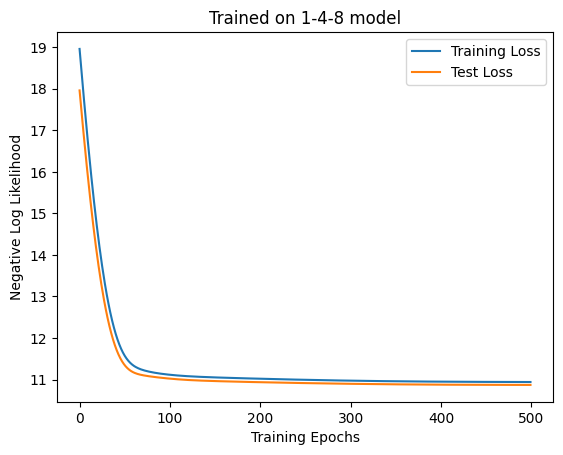
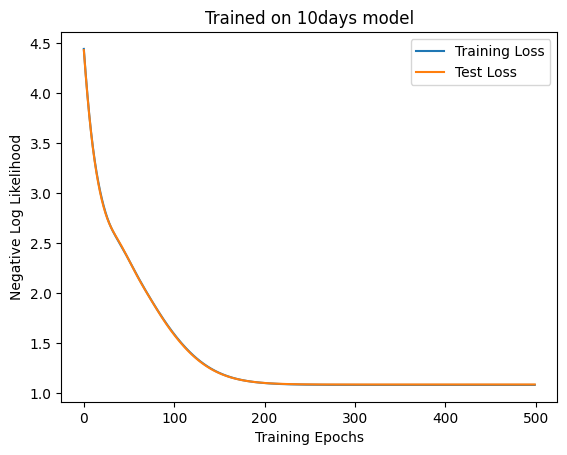
Next, let’s train some more complex data. This time, we will generate 11 days of weather in the following way: 1. Generate weather for days 1, 4, and 8 independently 2. Generate the weather for days 2 and 3 using a Markov chain with the weather for day 1 as the initial condition; generate the weather for days 5, 6, 7, 9, and 10 in the same way, based on the weather for days 4 and 8. 3. Generate the weather for day 11 stochastically based on the weather for days 1, 4, and 8.
Let’s see if the self-attention layer can learn this.
Code
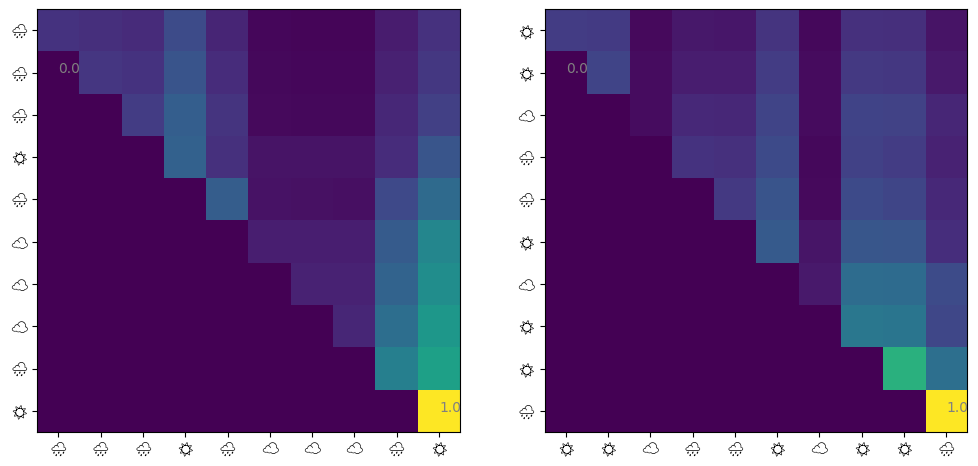
def _make_table() ->dict[str, list[float]]: candidates = []for i inrange(1, 9):for j inrange(1, 9):for k inrange(1, 9):if i + j + k ==10: candidates.append((i, j, k)) table = {}for i in WEATHERS:for j in WEATHERS:for k in WEATHERS: table[i + j + k] = [p /10for p in _GEN.choice(candidates)]return table_ONE_FOUR_8_TABLE = _make_table()def one_four_8(prev: str) ->str: length =len(prev) //2if length ==10: p = _ONE_FOUR_8_TABLE[prev[0: 2] + prev[6: 8] + prev[14: 16]]return prev + _GEN.choice(WEATHERS, p=p)elif length ==4or length ==8:return prev + _GEN.choice(WEATHERS, p=_MARKOV[""])else:return markov(prev)generate(one_four_8, 11)
It converged, but the accuracy is poor and the attention is also not very effective. Attentions are given to days 1, 4, and 8, but as in the previous experiment, the last day’s attention is larger.
Do we need attention?
As smart readers may have noticed, we don’t need self-attention to represent the two weather sequences we have learned so far. This is because the internal correlation of the input weather sequence has no bearing on the task at all, since the first one determines the weather of the previous day (day 10) and the next one determines the weather of days 1, 4, 8 to 11. So, let’s train with a linear model + softmax (the so-called multinomial logistic regression).
This looks better. So, when is the self-attention useful?
(Compared to MLP, etc.) when you don’t want to make the number of parameters depend on the length \(L\) of the token sequence
Note that in self-attention the number of parameters is \((d_\textrm{in} + 1)(2d_\textrm{attn} + d_\textrm{out})\), while in the linear model it is \((d_\textrm{in}L + 1)d_\textrm{out}\). In the linear model, the number of parameters increases linearly with the length of the token sequence. Note, however, that self-attention requires \(O(L^2)\) memory usage for \(q^\top k\), although Self-attention Does Not Need \(O(n^2)\) Memory shows an efficient \(O(\sqrt{L})\) implementation. Still, it may be consume more memory thatn simple RNN or CNN.
(Compared to RNN, CNN, etc.) when there is a long-term dependency in the token series
Compared to CNN and RNN, the advantage of self-attention is that \(q^\top k\) can represent arbitrary dependencies between tokens in one layer. However, since \(q^\top k[i, j]\) is obtained only by linear operations on the two embeddings \(e[i], e[j]\), if the two embeddings are dependent via some nonlinear function, the relationship cannot be represented by a single self-attention layer.
(Compared to RNN) when you want to do fast and parallel batch training
The operation of computing self-attention, namely the computation of \(\textrm{softmax}(q^\top k)\) can be parallelized per query. This is useful when you want to get a parallelized implementation that works fast on single or many GPUs.
So, although it has the advantage of not depending on \(L\) for the number of parameters compared to one linear layer, I am not sure if the self-attention can actually be more expressive or efficient. Let another blog post do some more theoretical stuff, I will try some more.
When there are hidden variables
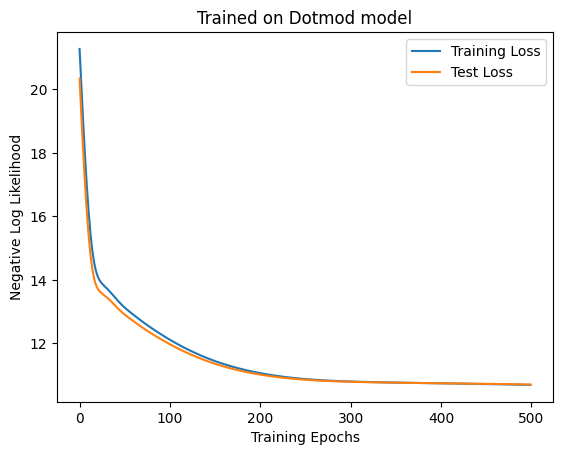
Generate a weather sequence in the following way. Look at the weather for the past \(n\) days, and if 🌧️ has appeared \(k\) times, let \(\frac{n - k}{2n}\) be the probability that the weather for the next day will be 🌧️. Assign probabilities for ☁️ and ☀️ in the same way. Generate a long weather sequence in this way and create a dataset by gathering randomly sampled subsequences.
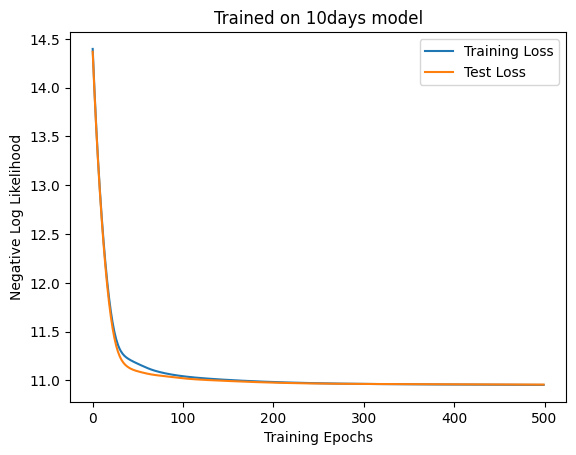
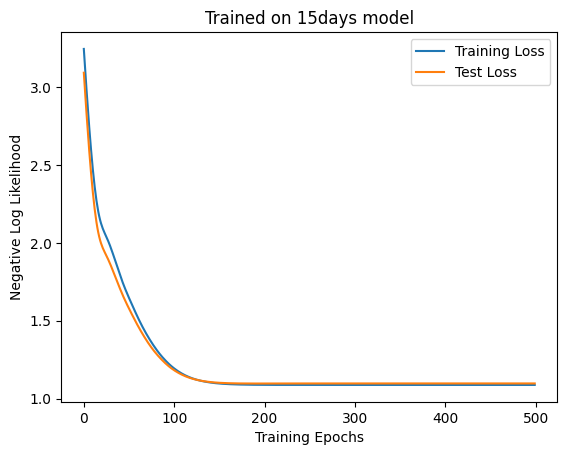
The self-attention is now worse than the linear model. Next, let’s turn the 10-day model into a 15-day model with hidden variables. First, we train the linear layer.
Attention is a bit better, but there is no meaningful difference in accuracy.
What about non-linear?
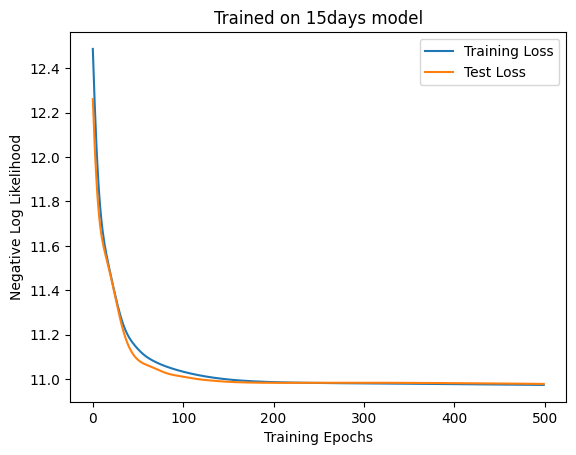
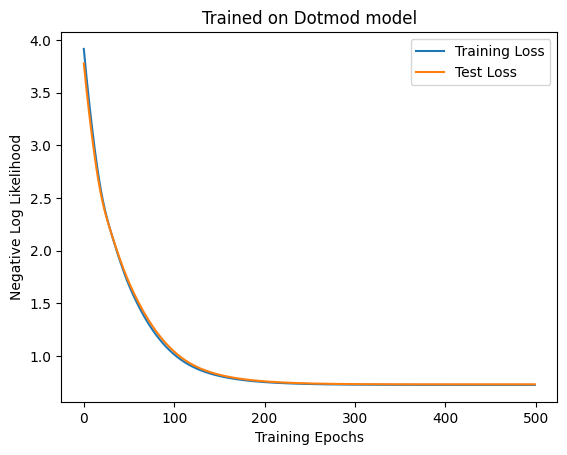
If the linear model performs better even with hidden variables, it probably means that the task is still linearly solvable. So let’s consider more difficult nonlinear data. Let \(y\) be a vector created by assigning 0, 1, and 2 to 🌧️, ☁️, and ☀️ in the 10-day weather sequence, respectively. Also, let \(\beta = (0, 1, 2, 3, 2, 1, 0, 1, 2, 3)^\top\). Let \((y(2 - y)\cdot \beta)\mod 3\) be the weather for the next day. To make the data a bit stohcastic, let’s assign other weathers 2% probability.
Again, the self-attention was not better. So maybe we can at least say that the self-attention itself is not very good at approximating nonlinear function like modulo.
Summary
In this blog post, I gave an overview of what the single self-attention, a simplified version of Multihead Attention in Transformer, is doing. I also tried to train it on some simple data sets. It ended up with less than linear function performance on all tasks and honestly could not see any benefit other than memory usage. Now I feel like MLP can be scaled as Transformer scaled in the infamous OpenAI paper. In future blogs, I will also want to try:
The effect of MultiHead Attention
Effects of Layer Normalization
Introduction of theoretical papers
Comparison with convolution, RNN, and linear state space models