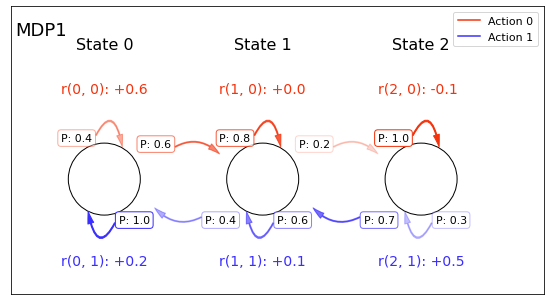
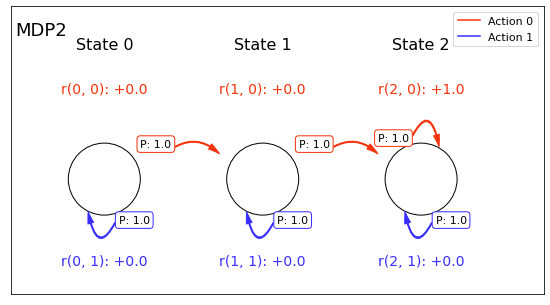
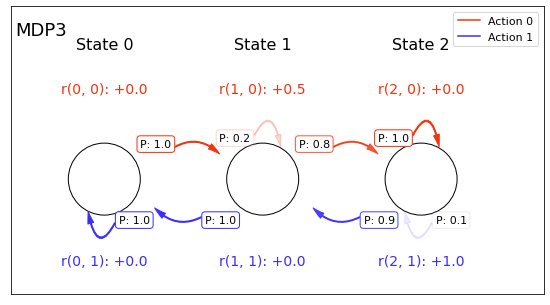
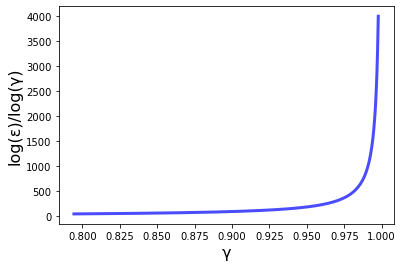
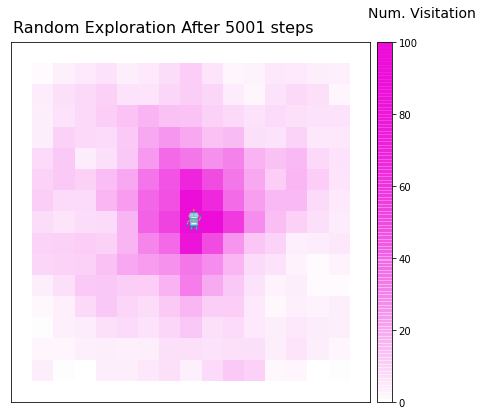
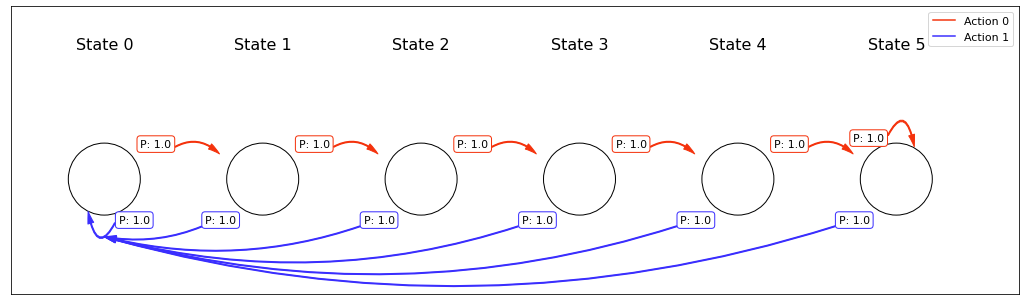
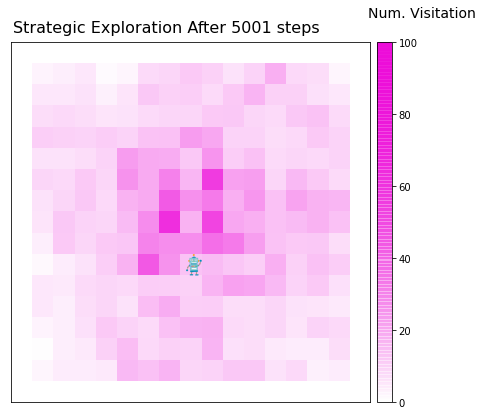
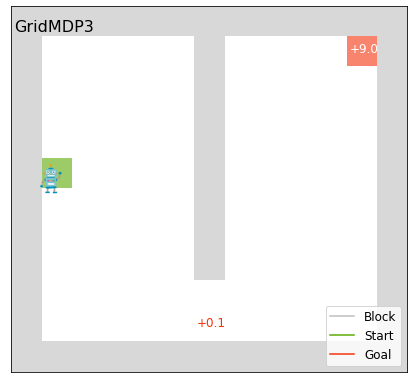
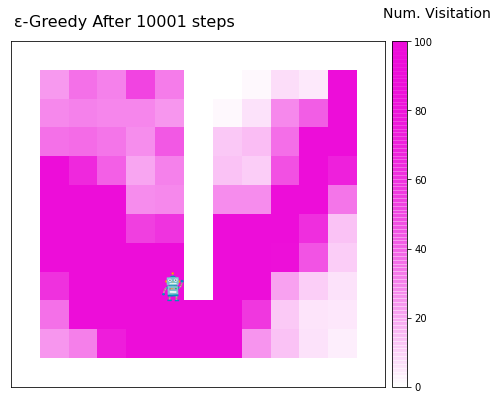
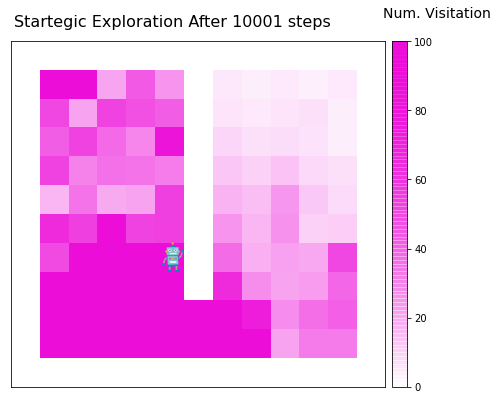
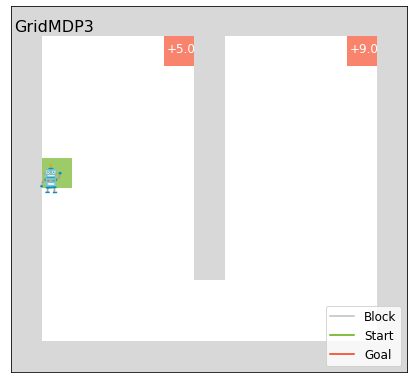
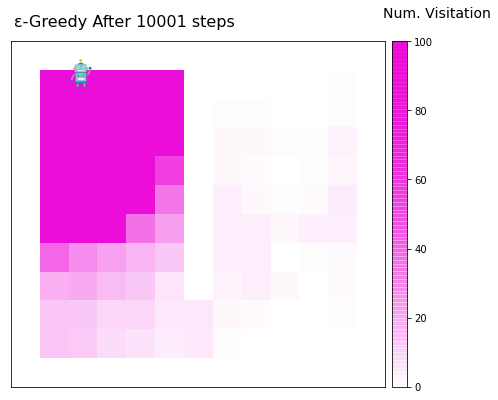
Code
from typing import Dict, List, Optional, Sequence, Tuple, TypeVar
import numpy as np
from matplotlib import pyplot as plt
from matplotlib.axes import Axes
from matplotlib.text import Annotation
# Some types for annotations
T = TypeVar("T")
class Array(Sequence[T]):
pass
Array1 = Array[float]
Array2 = Array[Array1]
Array3 = Array[Array2]
Point = Tuple[float, float]
def a_to_b(
ax: Axes,
a: Point,
b: Point,
text: str = "",
style: str = "normal",
**kwargs,
) -> Annotation:
"""Draw arrow from a to b. Optionally"""
STYLE_ALIASES: Dict[str, str] = {
"normal": "arc3,rad=-0.4",
"self": "arc3,rad=-1.6",
}
arrowkwargs = {}
for arrowkey in list(filter(lambda key: key.startswith("arrow"), kwargs)):
arrowkwargs[arrowkey[5:]] = kwargs.pop(arrowkey)
if len(text) > 0:
bbox = dict(
boxstyle="round",
fc="w",
ec=arrowkwargs.get("color", "k"),
alpha=arrowkwargs.get("alpha", 1.0),
)
else:
bbox = None
return ax.annotate(
text,
xy=b,
xytext=a,
arrowprops=dict(
shrinkA=10,
shrinkB=10,
width=1.0,
headwidth=6.0,
connectionstyle=STYLE_ALIASES.get(style, style),
**arrowkwargs,
),
bbox=bbox,
**kwargs,
)
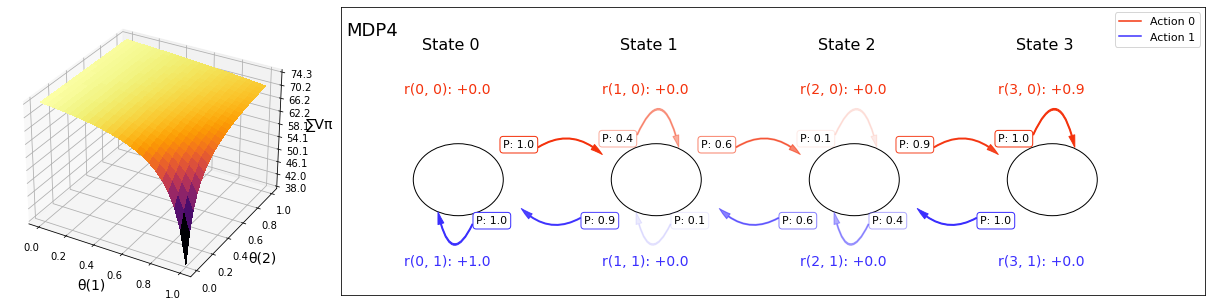
class ChainMDP:
"""Chain MDP with N states and two actions."""
ACT_COLORS: List[str] = ["xkcd:vermillion", "xkcd:light royal blue"]
INTERVAL: float = 1.2
OFFSET: float = 0.8
SHIFT: float = 0.5
HEIGHT: float = 4.0
def __init__(
self,
success_probs: Sequence[Sequence[float]],
reward_function: Sequence[Sequence[float]],
) -> None:
success_probs = np.array(success_probs)
self.n_states = success_probs.shape[0]
assert success_probs.shape[1] == 2
np.testing.assert_almost_equal(success_probs >= 0, np.ones_like(success_probs))
np.testing.assert_almost_equal(success_probs <= 1, np.ones_like(success_probs))
self.p = np.zeros((self.n_states, 2, self.n_states))
for si in range(self.n_states):
left, right = max(0, si - 1), min(self.n_states - 1, si + 1)
# Action 0 is for right
self.p[si][0][right] += success_probs[si][0]
self.p[si][0][si] += 1.0 - success_probs[si][0]
# Action 1 is for left
self.p[si][1][left] += success_probs[si][1]
self.p[si][1][si] += 1.0 - success_probs[si][1]
self.r = np.array(reward_function) # |S| x 2
assert self.r.shape == (self.n_states, 2)
# For plotting
self.circles = []
self.cached_ax = None
def figure_shape(self) -> Tuple[int, int]:
width = self.n_states + (self.n_states - 1) * self.INTERVAL + self.OFFSET * 2.5
height = self.HEIGHT
return width, height
def show(self, title: str = "", ax: Optional[Axes] = None) -> Axes:
if self.cached_ax is not None:
return self.cached_ax
from matplotlib.patches import Circle
width, height = self.figure_shape()
circle_position = height / 2 - height / 10
if ax is None:
fig = plt.figure(title or "ChainMDP", (width, height))
ax = fig.add_axes([0, 0, 1, 1], aspect=1.0)
ax.set_xlim(0, width)
ax.set_ylim(0, height)
ax.set_xticks([])
ax.set_yticks([])
def xi(si: int) -> float:
return self.OFFSET + (1.0 + self.INTERVAL) * si + 0.5
self.circles = [
Circle((xi(i), circle_position), 0.5, fc="w", ec="k")
for i in range(self.n_states)
]
for i in range(self.n_states):
x = self.OFFSET + (1.0 + self.INTERVAL) * i + 0.1
ax.text(x, height * 0.85, f"State {i}", fontsize=16)
def annon(act: int, prob: float, *args, **kwargs) -> None:
# We don't hold references to annotations (i.e., we treat them immutable)
a_to_b(
ax,
*args,
**kwargs,
arrowcolor=self.ACT_COLORS[act],
text=f"P: {prob:.02}",
arrowalpha=prob,
fontsize=11,
)
for si in range(self.n_states):
ax.add_patch(self.circles[si])
x = xi(si)
# Action 0:
y = circle_position + self.SHIFT
if si < self.n_states - 1 and 1e-3 < self.p[si][0][si + 1]:
p_right = self.p[si][0][si + 1]
annon(
0,
p_right,
(x + self.SHIFT, y),
(xi(si + 1) - self.SHIFT * 1.2, y - self.SHIFT * 0.3),
verticalalignment="center_baseline",
)
else:
p_right = 0.0
if p_right + 1e-3 < 1.0:
annon(
0,
1.0 - p_right,
(x - self.SHIFT * 1.2, y),
(x + self.SHIFT * 0.5, y - self.SHIFT * 0.1),
style="self",
verticalalignment="bottom",
)
ax.text(
x - self.SHIFT * 1.2,
y + self.SHIFT * 1.4,
f"r({si}, 0): {self.r[si][0]:+.02}",
color=self.ACT_COLORS[0],
fontsize=14,
)
# Action 1:
y = circle_position - self.SHIFT
if 0 < si and 1e-3 < self.p[si][1][si - 1]:
p_left = self.p[si][1][si - 1]
annon(
1,
self.p[si][1][si - 1],
(x - self.SHIFT * 1.6, y),
(xi(si - 1) + self.SHIFT * 1.4, y + self.SHIFT * 0.2),
verticalalignment="top",
)
else:
p_left = 0.0
if p_left + 1e-3 < 1.0:
annon(
1,
1.0 - p_left,
(x + self.SHIFT * 0.4, y),
(x - self.SHIFT * 0.45, y + self.SHIFT * 0.1),
style="self",
verticalalignment="top",
)
ax.text(
x - self.SHIFT * 1.2,
y - self.SHIFT * 1.4,
f"r({si}, 1): {self.r[si][1]:+.02}",
color=self.ACT_COLORS[1],
fontsize=14,
)
for i in range(2):
ax.plot([0.0], [0.0], color=self.ACT_COLORS[i], label=f"Action {i}")
ax.legend(fontsize=11, loc="upper right")
if len(title) > 0:
ax.text(0.06, height * 0.9, title, fontsize=18)
self.cached_ax = ax
return ax